Check out the Awesome-VLM-Data GitHub repo for compilation of relevant papers.
Learning with multiple modalities have been proved to be better than with just a subset of modalities in terms of minimizing the population risk due to the fact that multimodal learning can better estimate the latent space representation [1]. Despite the recent unprecendented progress in developing multimodal models, little analysis is done regarding the dataset used. The role of high-quality (and massive) datasets is indispensible in training capable VLMs. Hu et al. (2024) [2], for example, state that data is the main factor leading to CLIP success rather than the model architecture or pre-training objective. Other research [3] has demonstrated that a small contrastive image-text model trained exclusively on high-quality data is enough to build SOTA models.
While many surveys on VLMs have been conducted [4–8], few specifically focus on datasets. Given the crucial role of data in shaping model performance, this post explores the VLM data landscape, covering key aspects such as data curation, different data formats (image-text pairs vs. interleaved data), data filtering methods ,and the rise of synthetic data.
Data Curation
Image-text pair data
Prior to CLIP, most image-text data are created by combining different subsets of other publicly available image captioning datasets such as COCO [9], Visual Genome (VG) [10], and SBU captions [11]. Such curation method benefits from the high-quality human-labeled datasets. However, this kind of data is often limited in around hundreds of thousands image-text pairs due to the expensive labeling cost.
Contrary to these methods, CLIP [12] propose crawling images and their associated text by querying 500,000 words occurring at least 100 times in the English version of Wikipedia, obtaining a 400M-sample image-text pair data dubbed WebImageText (WIT). Figure 1 illustrates the general trend of dataset sizes scaling up significantly in the Post-CLIP era, although a few hundred-million-image captioning datasets have also been introduced. The largest image-text pair data, as writing date, is Google’s WebLI [13] with around 10 billions multilingual data samples (10 billions images and 12 billions alt-texts). Furthermore, OCR tools are also used, resulting in an additional 29 billion image-OCR pairs. However, only a subset of 1B filtered data pairs of the WebLI dataset is used to train the PaLI model.
Table 1 depicts the dataset curation and preprocessing/filtering method in more detail. Some preprocessing are left blank because they are not mentioned in the paper regarding how the data is preprocessed, which causes clear issues in terms of reproducibility.
| Dataset | Curation method | Preprocessing |
|---|---|---|
| LXMERT | MS COCO + VG + VQAv2 + GQA + VG-QA | Minimal preprocessing |
| UNITER | COCO+VG+CC3M+SBU Captions | Deduplicating images |
| CC12M | Images and their raw descriptions obtained from the Alt-text HTML attribute associated with web images. | Image-based and text-based (more relaxed compared to CC3M); image-text–based filtering. |
| ALBEF | COCO + VG + CC3M + SBU Captions + CC12M | |
| WIT400M (CLIP) | Search for (image, text) pairs whose text includes one of a set of 500,000 words occurring at least 100 times in the English version of Wikipedia. | |
| WIT | Extracting multiple different texts associated with an image from Wikipedia articles and Wikimedia image links. | Image-based and text-based; image-text–based filtering. Remove NSFW content, keeping only the top 100 languages. |
| ALIGN | Same as CC12M | Simple frequency-based filtering |
| FILIP-300M | Image-text pairs collected from the Internet + CC3M + CC12M + YFCC100M | Image-based and text-based; image-text pairs deduplication, YFCC100M filtering rules. |
| Red Caps | Collect data from a manually curated set of subreddits with a high volume of image posts | Image posts filtering and minimal text cleaning |
| PMD (FLAVA) | COCO + SBU Captions + Localized Narratives + CC3M + VG + WIT + CC12M + Red Caps + YFCC100M (filtered) | Discard non-English captions and only keeping captions with more than two words |
| LiT | Same as ALIGN | Image-based filtering same as ALIGN, text-based filtering, remove near-duplicate images |
| LAION-400M | Parse through WAT files from Common Crawl and parse out all HTML IMG tags containing an alt-text attribute. | Length & Size Filtering, Deduplication, Relevance Filtering (cosine similarity threshold from CLIP embeddings), Illegal Content Filtering |
| FLD-900M (Florence) | Employ a programmatic data curation pipeline that processes around 3 billion Internet images and their raw descriptions. | Image deduplication, small-size image removal, image-text relevance, CLIP sampling strategy |
| COYO-700M | Collected about 10 billion pairs of alt-text and image sources in HTML documents in CommonCrawl. | Image-based and text-based; image-text filtering |
| BASIC | Extend ALIGN with 5B image-text pairs from JFT, converting class labels into text sequences. | Text filtering and filter duplicated pairs based on structural similarity index |
The curation methods can roughly be classified into two categories: 1) combining pre-existing image captioning data subsets [14], uniter, albef or 2) crawling from the web with alt-text HTML attribute [12, 15–23].
Interleaved Image-text data
Along with image-text pair datasets, another kind of dataset that is often used to train VLMs is interleaved image-text pair. An example of the difference between two types of datasets is illustrated in Figure 2.
CM3 [24] introduce the dataset with 223 billion number of tokens crawled from CC-News and English Wikipidea. For each <img> tag with a valid src URL, the image is downloaded and tokenized with VQVAE-GAN. The tokens are then inserted into the original text, replacing the src attribute. Flamingo [25] propose a dataset called M3W, which are text and images extracted from ~43 million webpages. The tags are inserted into the plain text where images appear and adding a learned
Another notable dataset is Facebook’s Chameleon [26], with 400 billion tokens and the filtering process is the same as OBELICS [27]. Very little detail is provided in the paper.
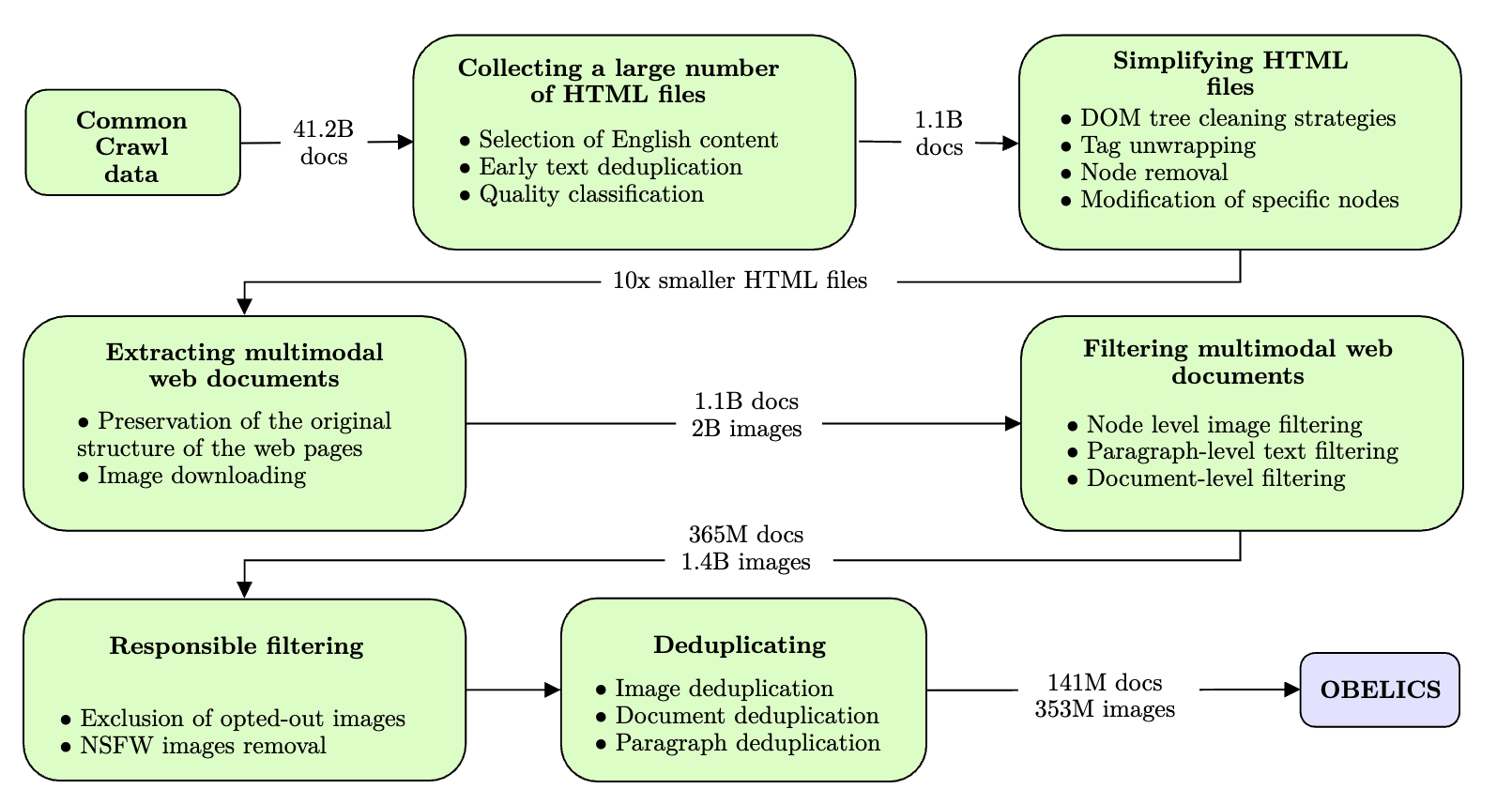
The dataset used to train CM3, Flamingo, and Chameleon, however, is proprietarty. Attempts to curate open interleaved therefore have been made. OBELICS [27] is an open interleaved dataset curated from 141 million multimodal English web documents. The final dataset has 115 billion tokens. The overall workflow of OBELICS curation is depicted in Figure 3.
Another notable interleaved image-text dataset is Multimodal-C4 (MMC4) [28], an extension of the C4 corpus [29], where images are assigned to sentences using a bipartite linear assignment approach with CLIP ViT-L/14 for alignment. The dataset includes subsets like mmc4-ff (face-filtered) and mmc4-core (strictly filtered), ensuring diverse yet well-aligned image-text sequences. Initial evaluations show effective NSFW/ad removal, strong intra-document alignment, and promising applications, including improving few-shot learning in models like OpenFlamingo.
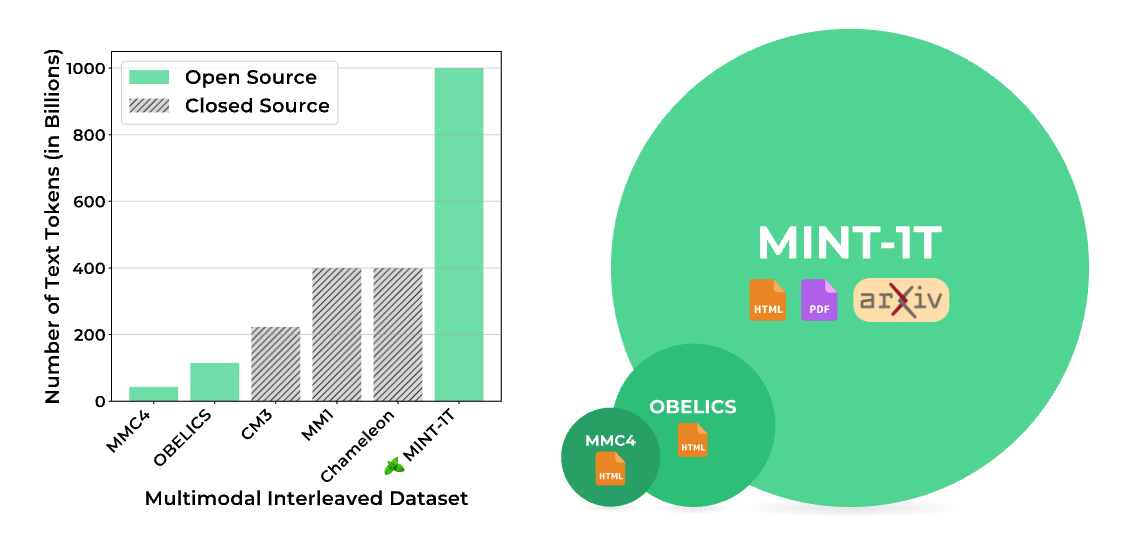
MINT-1T [30] is a large-scale open-source dataset that aggregates diverse interleaved documents, including PDFs and ArXiv papers (which is untapped in previous dataset curation). It undergoes rigorous filtering, deduplication, and NSFW content removal to ensure high quality. The final dataset comprises 922B HTML tokens, 93B PDF tokens, and 9B ArXiv tokens, totalling around 1 trillion tokens (see Figure 4).
All of the aforementioned datasets, however, apply non-English data sample filtering, restricting it usage to only English. mOSCAR [31] is the first large-scale multilingual and multimodal document corpus, covering 163 languages, 315M documents, 214B tokens, and 1.2B images. It is sourced from three 2023 Common Crawl dumps, processed using FastWARC, with documents under 500 bytes removed to reduce noise. The dataset is extracted using a depth-first search through the DOM tree, leveraging the ChatNoir library for targeted HTML tag retrieval. Another dataset that contain multiple (two) languages is OmniCorpus [32], a 1.7-trillion-token dataset curated from Common Crawl and Chinese websites, making it a bilingual and largest interleaved data to date.
Data Filtering
The data filtering process for VLMs can roughly be divided into four different kinds, including (1) image-based filtering, (2) text-based filtering, (3) image-text filtering, and (4) model-based filtering. Different datasets employ different filtering methods, as given in Table 1. The first three kinds of filtering are often heuristic and is hand-designed based on a specific set of rules (image resolution/ratio, sequence length, etc), while model-based filtering employs other models, often to extract features for similarity computation. Table 2 gives a detailed descriptions of data filtering methods as employed in DataComp.
| Filtering Method | Description |
|---|---|
| Basic Filtering | Selects data based on fundamental criteria such as English captions, specific caption lengths, and minimum image sizes to ensure data quality and relevance. |
| CLIP Score Filtering | Utilizes the cosine similarity between CLIP’s image and text embeddings, retaining only examples where the similarity exceeds a predefined threshold, indicating a strong correspondence between image and caption. |
| Text-Based Filtering | Chooses captions that contain words overlapping with ImageNet’s labels, ensuring that the textual descriptions are closely related to recognized object categories. |
| Image-Based Filtering | Selects a subset of examples whose visual content overlaps with ImageNet classes, ensuring that the images correspond to known categories and enhancing the relevance of the dataset. |
Text-based filtering
In a work by Alex et al. (2024) [33], the dataset is cleaned using three filtering steps: (i) a bad-word list from the better-profanity library, which automatically excludes most samples (around 14,000) and marks 18 potentially non-profane words for human review; (ii) a profanity-check model using an SVM, which filters 482 samples; and (iii) manual annotation, which removes 114 offensive samples. In total, these steps filter 14,322 samples, approximately 3% of the dataset.
MetaCLIP [2] replicates OpenAI CLIP’s data curation by using substring matching to filter low-quality text and structuring unstructured data with metadata. It balances data distribution by capping metadata matches at 20k, reducing noise and enhancing diversity for task-agnostic pre-training. Training on MetaCLIP-400M improves CLIP-ViT-L/14’s zero-shot image classification from 65.7 to 67.1.
Image-based filtering
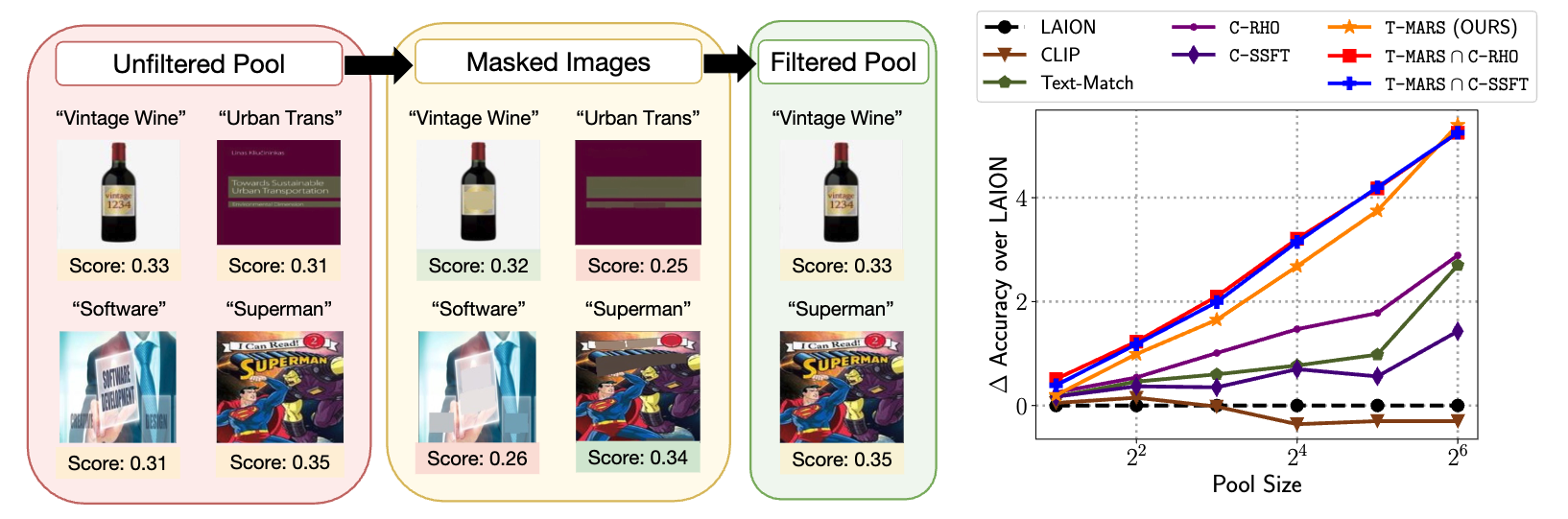
Stemming from the observation that LAION-5B has nearly 40% images which contain text that overlaps significantly with the caption, T-MARS [34] first mask the text in the images and keep only the data points with the highest similarity scores instead of feeding the image-text pair directly into CLIP, as shown in Figure 5.
CAT filtering [35] extends T-MARS by removing image-text pairs where MMOCR detects text with \(\geq\) 0.8 confidence and \(\geq\) 5 matching characters in a sliding window. It also filters captions based on complexity, defined as the maximum number of relations to any object in the parse graph, and retains only samples with at least C1 complexity. To further exclude pairs likely depicting products, captions are filtered out unless they contain at least one action.
Model-based filtering
For model-based filtering, an exemplary work is CLIPScore [36] that has been widely used for constructing large-scale datasets like COYO-700M and LAION-400M [17], laion-400m. The CLIPSCore is defined as the cosine similarity between each pair of image-text CLIP embeddings as follows:
\[ \texttt{CLIP-S}(\mathbf{c,v}) = w * \max (cos(\mathbf{c,v}),0), \]
where \(\bf{c}\) is the textual embedding, \(\bf{v}\) is the image embedding, and \(w\) is the scaling factor. One advantage of CLIPScore is that it does not need a reference sample compared to prior captioning metrics like BLEU, ROUGE, or CiDER.
Empirical results from DataComp [37] show that in general, for data that is above the medium scale, the filtering strategies that work best is to combine CLIP Score and Image-based filtering. For small scale dataset (1M-3M samples), CLIP Score alone yields the best average performance on 38 different downstream tasks, as shown in Table 3.
| Scale | Filtering Strategy | Dataset Size | Samples Seen | ImageNet | ImageNet Dist. Shifts | VTAB | Retrieval | Average Over 38 Datasets |
|---|---|---|---|---|---|---|---|---|
| small | CLIP score | 3.8M | 12.8M | 0.051 | 0.055 | 0.190 | 0.119 | 0.173 |
| Image-based ∩ CLIP score |
1.4M | 12.8M | 0.039 | 0.045 | 0.162 | 0.094 | 0.144 | |
| medium | CLIP score | 38M | 128M | 0.273 | 0.230 | 0.338 | 0.251 | 0.328 |
| Image-based ∩ CLIP score |
14M | 128M | 0.297 | 0.239 | 0.346 | 0.231 | 0.328 | |
| large | CLIP score | 384M | 1.28B | 0.578 | 0.474 | 0.538 | 0.466 | 0.529 |
| Image-based ∩ CLIP score |
140M | 1.28B | 0.631 | 0.508 | 0.546 | 0.498 | 0.537 | |
| xlarge | CLIP score | 3.8B | 12.8B | 0.764 | 0.655 | 0.643 | 0.588 | 0.650 |
| Image-based ∩ CLIP score |
1.4B | 12.8B | 0.792 | 0.679 | 0.652 | 0.608 | 0.663 |
MLM-filter [38] propose a three-stage pipeline for data filtering, including 1) fine-tune an MLM for quality assessment, 2) use it to filter high-quality data, 3) pre-train VLMs on the filtered data and evaluate on downstream tasks. However, an important thing to note here is that prior research work [3] have shown that the quality of a network for filtering is not necessarily correlated with its performance on downstream tasks. Empirical results show that using MLM Filter improves CLIP’s zero-shot performance on the large scale of DataComp benchmark.
Data Filtering Networks (DFNs) [3] filters image-text pairs based on similarity embeddings. It finds that a DFN’s accuracy on a task doesn’t directly predict its effectiveness in data selection. Training DFNs on high-quality datasets and fine-tuning them improves performance across tasks, even at different data scales. Table 4 table highlights the performance improvements of DFN datasets across different DataComp scales and model architectures, showing consistent gains over other datasets. Notably, DFN-2B and DFN-5B outperform alternatives like LAION-2B and OpenAI WIT-400M, with DFN-5B achieving the highest average score (0.710) when scaled to ViT-H/14-378px.
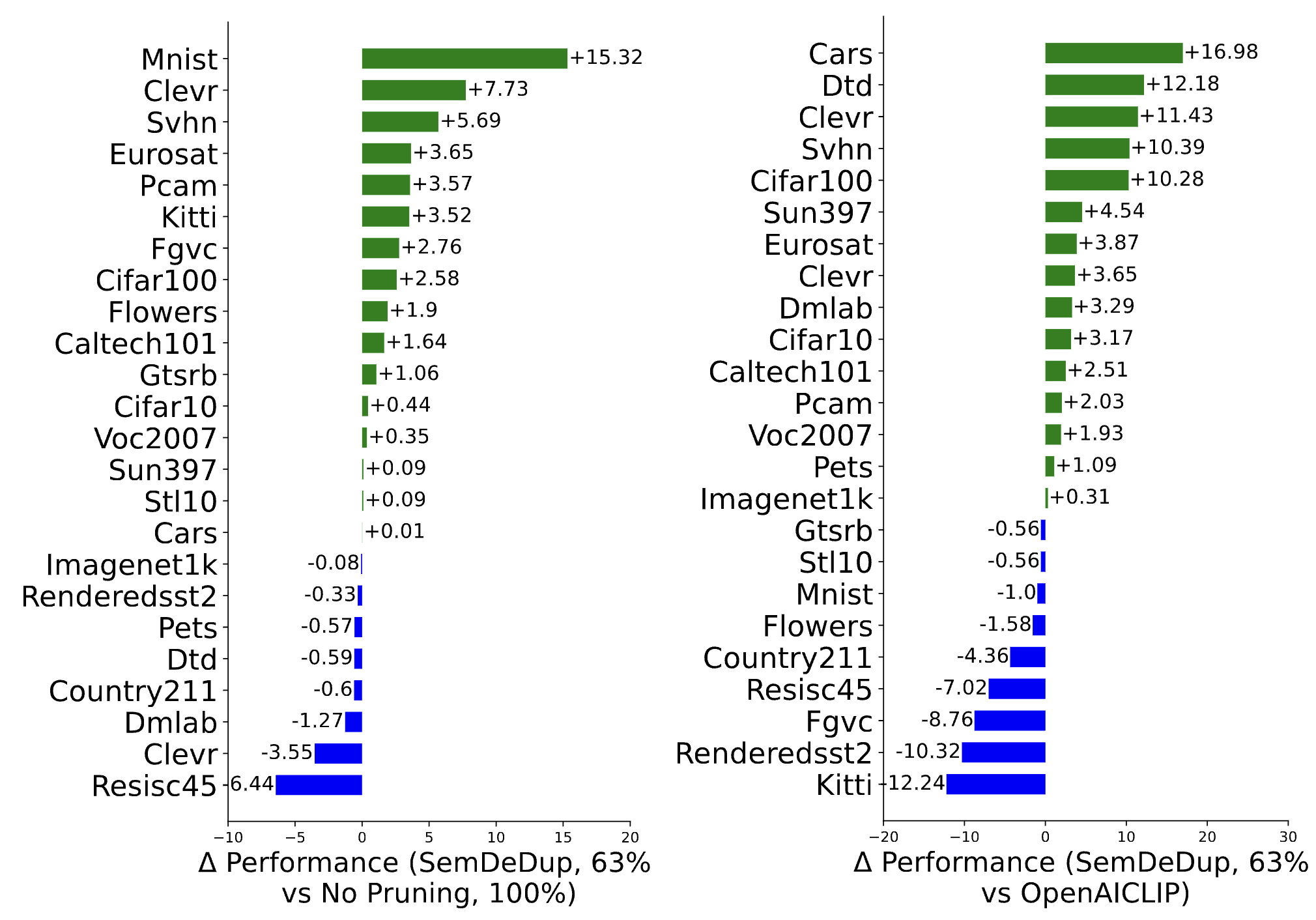
SemDeDup [39] uses CLIP to filter out semantically identical data pairs, showing improved performance on zero-shot image classification with just 63% subset of LAION-400M. SemDeDup detects semantic duplicates in the embedding space, using clustering to make large-scale comparison feasible. Applying it to datasets like LAION reveals that 50% of examples have semantic duplicates, allowing for a 50% reduction in training data with minimal performance loss and 2x faster learning. Figure 6 illustrates the effectiveness of SemDeDup on zero-shot and OOD image classification tasks.
Given that we already have the high-quality datasets, one question is how useful would these data be as we increase the amount of computation (i.e. training the model for more epochs) ?
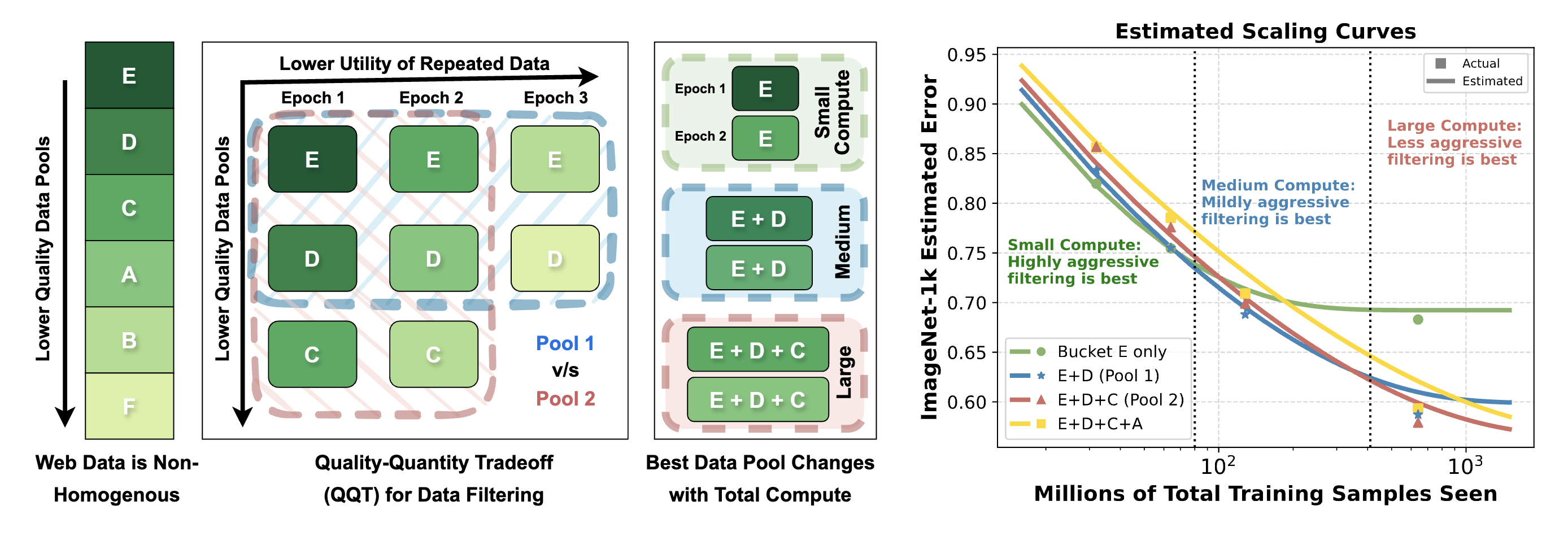
Goyal et al. (2024) [40] introduce a scaling law and show that the ultility of high-quality datasets would decrease as we increase the number of epochs, as illustrated in Figure 7. In particular, the benefit of data filtering steadily declines as the compute budget increases. Notably, after 450M iterations, training on the unfiltered Common Crawl dataset surpasses that on LAION-filtered data.
Synthetic Data
As the datasets used to train VLMs are becoming bigger, it’s actually becoming non-trivial that we’ll run out of datasets. This creates an urge to ultilize other off-the-self models to create synthetic datasets. This section introduces recent techniques that employ the use of pre-trained models (either LLM or VLM) to synthesize new datasets, forming a bootstrapping procedure to train VLMs. This section outlines current research direction on enriching data for VLM training, from rewriting/generating image captions to image synthesis. We’ll also delve into why and in what case is synthetic data beneficial.

Rewriting the captions
One of the most well-studied directions in terms of improving the datasets is rewriting the captions. BLIP [41] is one of the most notable model that follows this synthetic approach by traininng a captioner to rewrite the noisy web image captions. An additional filter is used to further enhance the dataset quality. Ablation study shows that the use of captioner increase the model’s performance on image captioning and retrieval tasks.
LaCLIP [42] employs LLM (LlaMA) to rewrite the captions in well-established captioning datasets such as CC12M and RedCaps. LaCLIP enhances CLIP’s performance in both zero-shot and few-shot image classification tasks. When trained on the CC12M dataset, LaCLIP method improves 8% on top-1 accuracy on ImageNet and 7% improvement on average over the other downstream datasets compared to the vanilla CLIP model.
However, as noted by Nguyen et al. (2023) [43], LaCLIP assumes access to raw text and that the image captioner is not conditioned on the image, which may limit effectiveness when captions lack descriptiveness. Additionally, since LaCLIP utilizes datasets like CC12M, which already contain high-quality captions, VeCLIP [44] argues that using large language models to rewrite noisy alt texts may yield only trivial improvements. VeCLIP therfore first use LLaVA [45] as an intial image captioners to generate image captions, then they incorporate the generated captions and alttexts using LLMs, yielding the final captions dubbed VECaps. Training the VeCLIP model WIT dataset with VeCaps is shown to improve the model’s performance on both image classification and retrieval tasks.
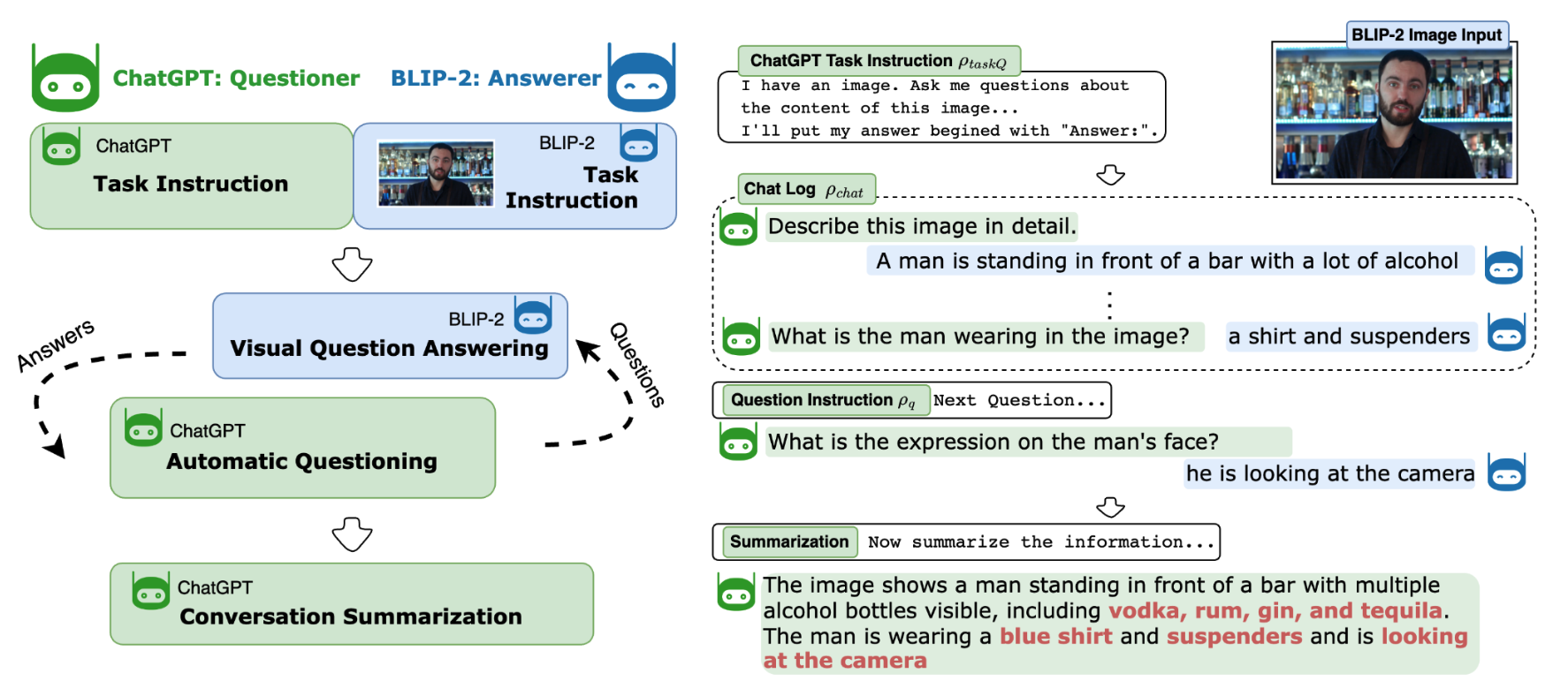
ChatCaptioner [46] ChatGPT to ask BLIP-2 a series of question relating to the input image. Then, the final description/summarization is generated by BLIP-2, which is used as the new image captions containing more visual details. The overall pipeline is shown in Figure 8. This approach is shown to contain more information and number of object in image captions.
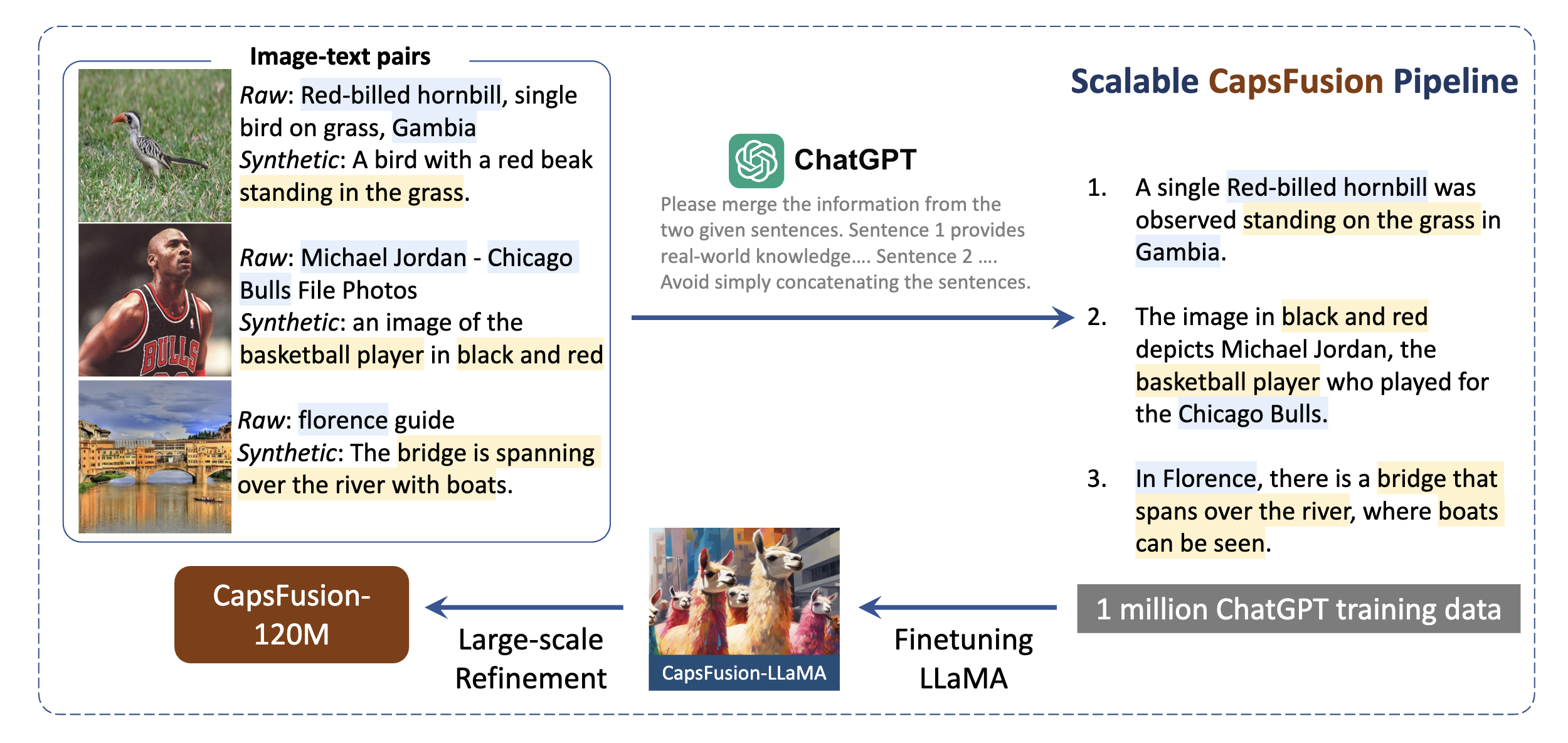
The use of proprietary models like ChatGPT, however, might be restrictive. CapsFusion [47] therefore first generating the image captions using BLIP [41], use LlaMA-2 model [48] fine-tuned on ChatGPT’s outputs to fuse the synthetic and original captions. Compared to other works, CapsFusion focuses on training Large Multimodal Models (LMMs) rather than CLIP, as shown in Figure 9
On a similar vein, Recap-DataComp-1B [49] train a LlaVA model that use LlaMA-3 as the LLM backbone on image captioning task and then use this model to recaption the DataComp-1B dataset. The generated captions has on average a sequence length 49.5, compared to 10.2 of the original captions from DataComp-1B. Training the model on this new dataset with đifferent mixing ratio (of synthetic and raw captions) yeilds improved results on top-1-recall retrieval task.
FuseCap [50] uses vision experts (i.e. object detectors, attribute recognizers, and OCR models) to extract the visual information from the image and then incorporate these information with the original captions using LLMs. The FuseCap dataset, with 12M generated captions, improves image captioning and retrieval tasks. A BLIP-like model fine-tuned on FuseCap achieves higher CLIPScore and better COCO retrieval performance compared to BLIP2.
VILA² [51] observes diminishing returns when rewriting captions. After the fourth iteration, the quality of the captions no longer improves, often due to limitations in the capacity of the captioning model. To address this, they propose enhancing the model with more specialized vision tasks, such as spatial and grounding understanding or OCR, by fine-tuning the VILA model to further improve the results.
CLIPS [52] shows that a subset of the caption surprising leads to better performance rather than feeding full-length (synthetic) captions. ALIP [53] uses OFA model [54] to generate synthetic captions. Instead of hand-tuning the mixing ratio of synthetic and original data samples [49], laclip, gadre2023datacomp, ALIP proposes the use of Language Consistency Gate (LCG) and Description Consistency Gate (DCG) to adaptively adjust the weight of the synthetic caption and the intial raw text in the contrastive loss during model training. When pre-trained on YFCC15M, ALIP yields SOTA results on image and text retrieval metrics.
Synthetic caption effectiveness.
Nguyen et al. (2024) [43] investigates the benefits of synthetic captions for VLMs’ performance. The two main findings are that (1) Higher CIDEr scores do not necessarily lead to better captions for training CLIP. For instance, OpenCLIP-CoCa ViT-L/14 achieves a relatively low CIDEr score of 0.354 yet attains the highest ImageNet classification score (0.321). In contrast, models with CIDEr scores between 80–120 perform worse, with scores ranging from 0.2 to 0.28. (2) Synthetic captions tend to be longer and contain more visual tokens than raw captions. CLIP score filtering on raw captions, as well as mixing raw and synthetic captions, enhances these properties, ultimately improving caption quality.
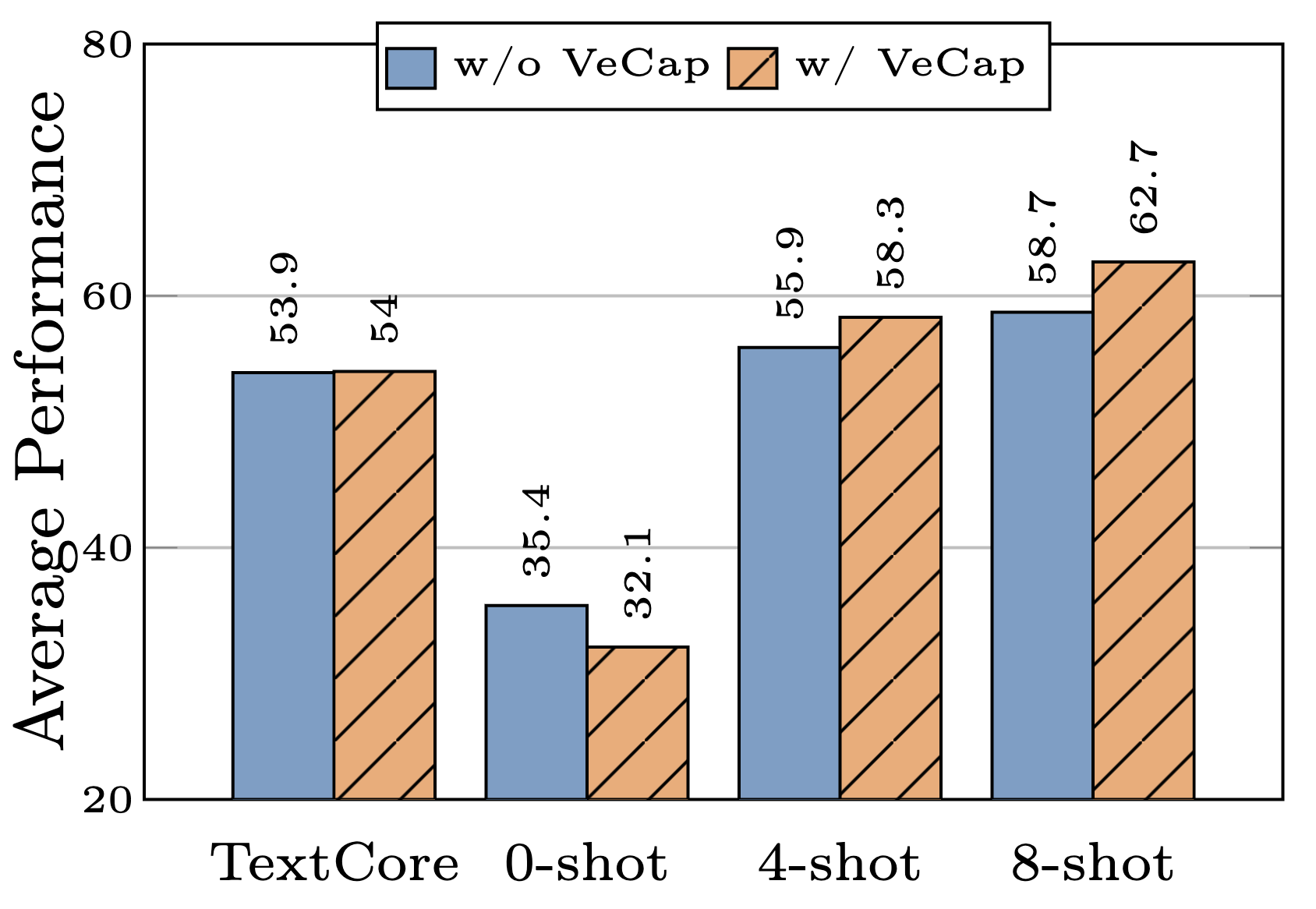
The use of synthetic captions, however, is not always beneficial. MM1 [55] shows that incorporating high-quality synthetic data like VeCap [44] enhances few-shot learning. Despite making up only 7% of all caption data, it significantly boosts performance by 2.4% and 4%. While VeCap slightly improves performance in TextCore and significantly boosts results in 4-shot and 8-shot scenarios. However, it negatively impacts 0-shot performance, leading to a decrease of 3%, as shown in Figure 10.
Images Synthesis and Fully Synthetic Data Training
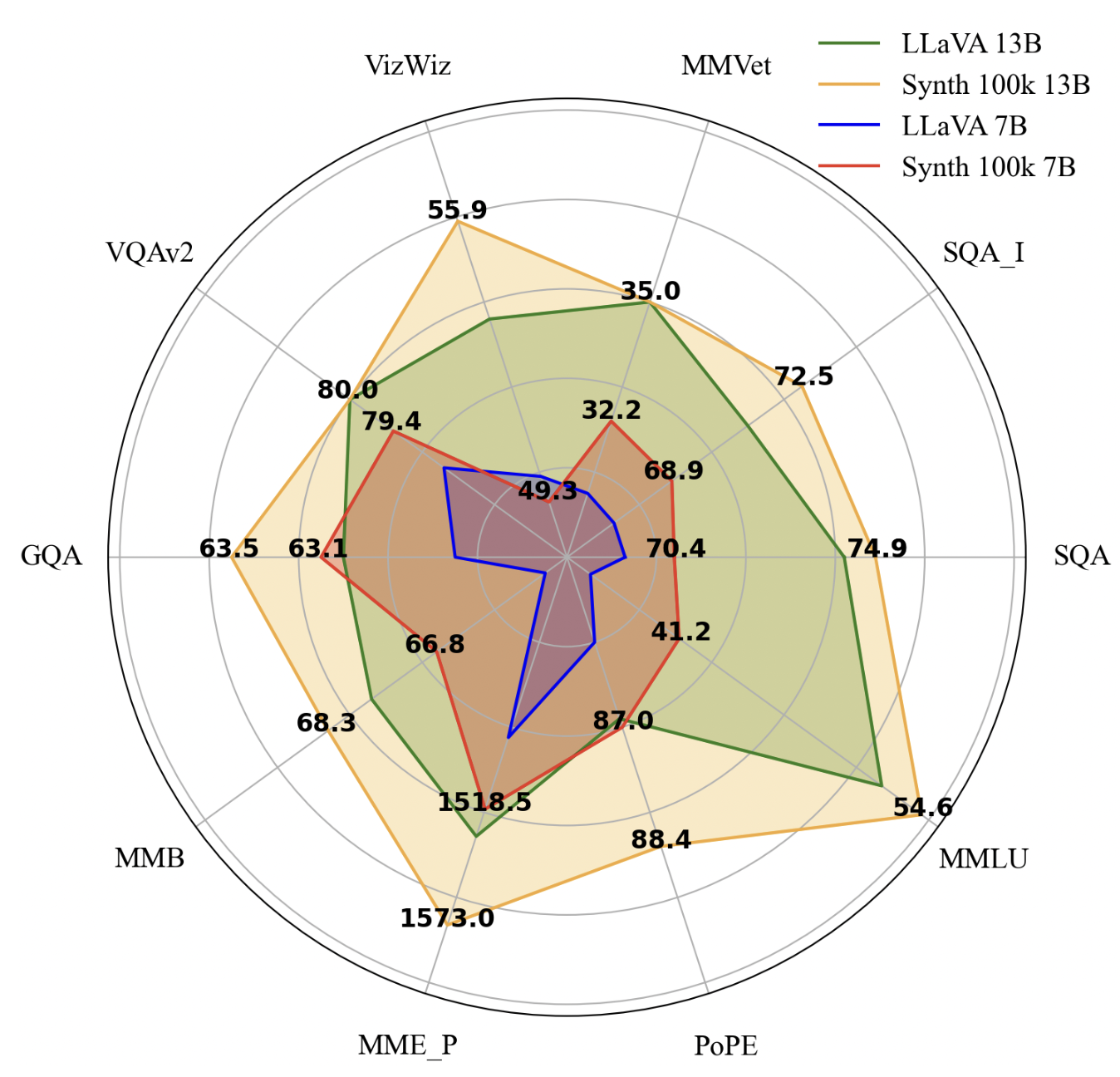
SynthVLM [56] uses Stable Diffusion to create images from a set of filtered captions compiled from a range of captioning datasets such as CC and SBU, retaining 40% of the original dataset. A subset of 1000 captions is randomly samples to feed into Stable Diffusion model for image generation. The generated images have resolution of 1024x1024. The resulting dataset is shown to have higher CLIPScore (0.34 and 0.38 compared to 0.32 and 0,31 in the raw datasets). Empirical experiments using SDXL for image generation and LLaVA 1.5 (13B) for robust visual understanding, employing CLIP 336 (14-patch) as the encoder and Vicuna v1.5 (13B) as the language model. The model trained on 100k synthetic data samples achieves SoTA across multiple visual and language benchmarks while reducing computational usage.
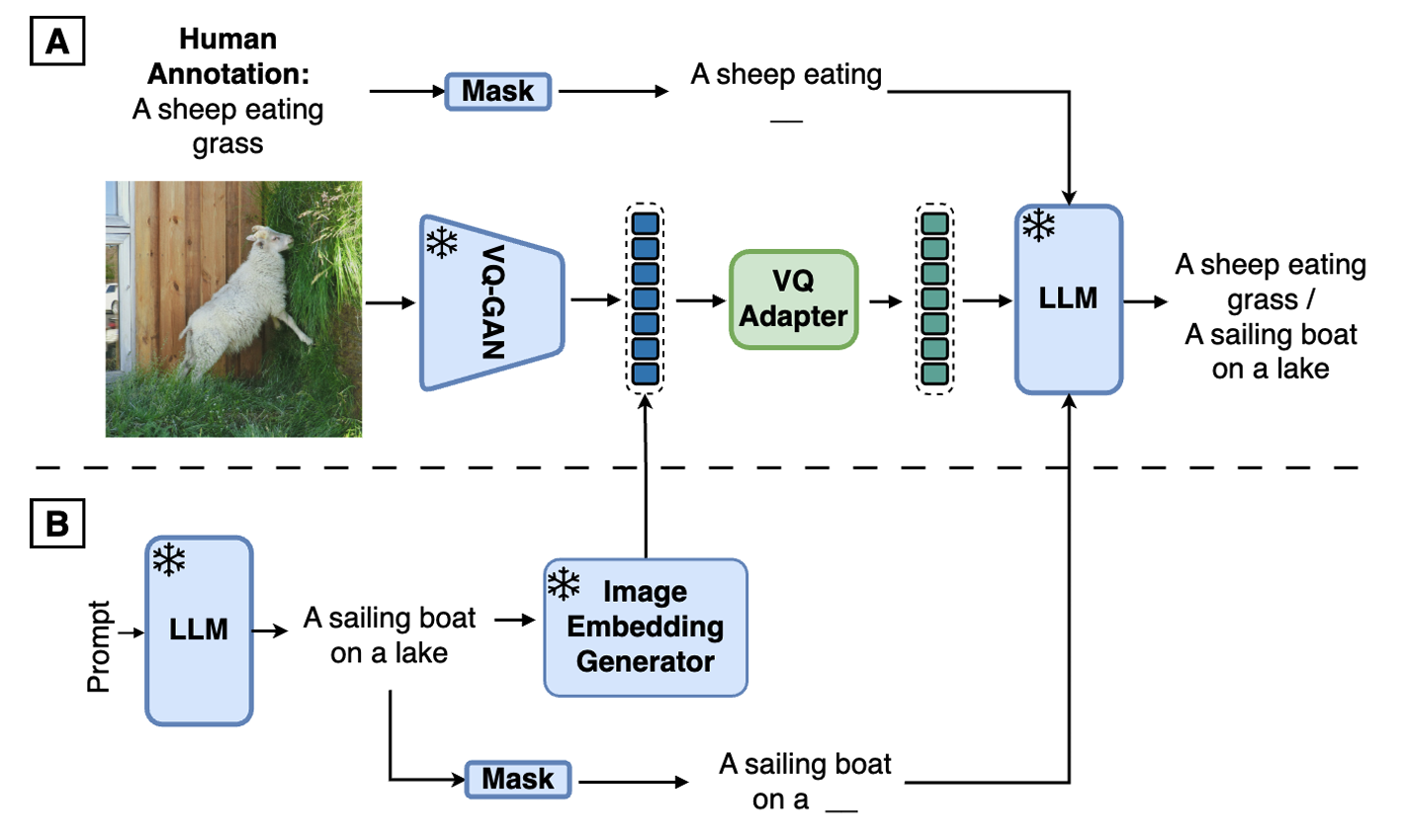
Synth² [57] develop a pipeline to create an entirely synthetic datasets, both the captions and images. Using Gemini Pro, the captions are first created with classes from ImageNet datasets. These captions are then uses to prompt a text-to-image model to create synthetic images. The overall architecture of Synth² is depicted in Figure 12.
However, rather than generating images in the pixel space, this work generate the images in the embedding space and use it to directly train the VLM. Table 8 shows that adding 1M synthetic samples (GenPair) improves the zero-shot evaluation result significantly compared to training the model on 1M additional data samples from WebLI [13] or LTIP [25] dataset. Concurrent to Synth², SynthCLIP [58] starts from building a concept bank containing \(N_C\) concepts similar to MetaCLIP [2] and prompt the Mistral-7B-Instruct V0.2 model to create the image
captions. The generated captions are then filtered by substring matching to determine concept frequencies and probability balancing to prevent over-representation of common concepts while boosting long-tail concepts. This ensures a diverse and task-agnostic caption set suitable for foundation model pre-training, similar to MetaCLIP [2]. These filtered captions are then used as inputs to Stable Diffusion for image generation, resulting in the final 30M-sample dataset called SynthCI. SynthCLIP is trained on the synthetic dataset SynthCI at varying scales. As the size of SynthCI increases, a consistent improvement in performance is observed across both vision and vision-language tasks, rivaling with the performance of CLIP models trained on CC3M and CC12M.
Data Augmentation
Popular datasets like LAION [21, 22] have been shown to exhibit a long-tailed distributions, which might lead to bias when training the models. Contrary to traditional datasets, where concept frequency estimation is straightforward that we can just count the number of classes, pre-training datasets for VLMs, however, the task of concept frequency estimation is non-trivial because of the variations in natural language. For example, sneakers can also be referred to in the dataset as running shoes or trainers. Parashar et al. (2024) [59] address this by using LLMs to list the synonyms (eg. tiger, Panthera tigris, …).
Furthermore, to filter out irrelevant pretraining texts, simple string matching is insufficient due to linguistic ambiguities, so Llama-2 is used to verify whether a retrieved caption’s concept matches its intended definition, excluding mismatched cases to ensure accurate concept frequency estimation. This strategy is called REAL-Prompt and it is shown to enhance accuracy and efficiency, outperforming methods like DCLIP and CuPL while significantly reducing token usage and cost.
Another variant of REAL-Prompt, called REAL-Linear, retrieves concept-relevant images from pretraining data to create a more balanced subset for training a robust linear classifier (see Figure 13 for an illustration). REAL-Linear achieves SOTA performance, outperforming REACT by 3% in accuracy while using only 1% of its compute, with additional gains from synonym expansion, cross-modal learning, and optimized retrieval size, benefiting both head and tail classes.
Most approach consider CLIP’s embedding on a Euclidean space, creating two separated clusters for image and text. \(m^2\)-Mix [60] addresses this by mixing image and text embeddings through multi-modal Mixup, ensuring the mixed embeddings remain on CLIP’s hypersphere using a novel geodesic Mixup approach (see Figure 13). Unlike standard Mixup, which does not guarantee hypersphere alignment, geodesic Mixup interpolates along a geodesic path to maintain this property.
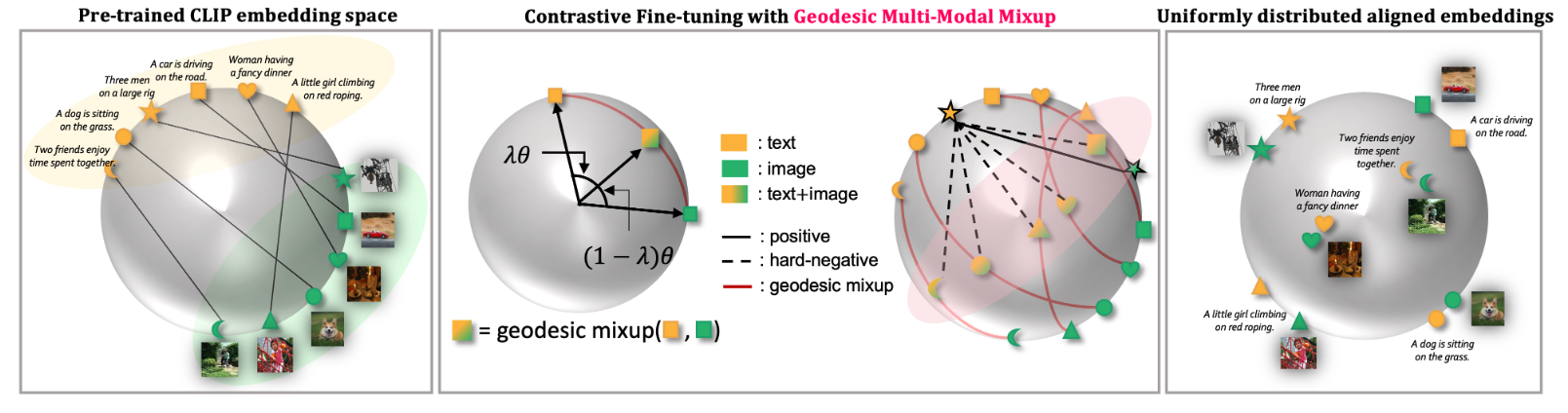
\(m^2\)-Mix can be considered a data augmentation method in the embedding space rather than the input space. Traditional data augmentation techniques (e.g. cropping, flipping, or color jittering) modify raw input data, while \(m^2\)-Mix augments the feature representations by generating virtual samples through multi-modal Mixup.
Since it creates hard negative samples that improve contrastive learning by better distinguishing between similar concepts, it aligns with the goal of augmentation: expanding the training distribution to enhance model robustness. This is particularly useful for contrastive learning-based models like CLIP, where embedding space augmentation can lead to better generalization. \(m^2\)-Mix consistently enhances representation learning across various tasks, including cross-modal retrieval, uni-modal and multi-modal classification, and image captioning, by effectively aligning mixed embeddings from different modalities. It achieves notable performance gains, particularly in fine-tuning scenarios, with improvements observed across multiple datasets and models.
Multilinguality
A common practice in training VLMs is to filter out non-English data samples from massive web-scraped datasets [12, 18], which lead to potential biases. For example, CLIP filter tends to keep only Western-related data points, excluding those that are non-Western. In particular, English data samples have a pass rate of approximately 0.5, while that of Korean and Chinese data is below 0.1.
In attempt to address the problem of English-dominant web-scaled datasets, Nguyen et al. (2024) [61] translate non-English data samples from DataComp-128M dataset to English. Empirical results show consistent improvement when using the translated data samples. The conjecture for this improvement is that multilingual data enriches monolingual data distribution by adding cultural insights and diverse annotations for the same visual category.
On the DataComp benchmark, training on translated captions outperforms training on raw captions across multiple metrics, including ImageNet accuracy, distribution shifts, retrieval, and GeoDE worst-region accuracy. Using both translated and raw captions together yields even greater performance gains, with the best results achieved by tuning the filtering threshold for each baseline.
Google PaLI-X and Ying-VLM [62], ying-vlm both leverage multilingual training to enhance vision-language understanding across diverse languages. PaLI-X, trained on the WebLI dataset covering 100 languages, achieves state-of-the-art results in 5 out of 7 languages on the XM-3600 multilingual image captioning benchmark, while Ying-VLM, trained on the Multi-Modal, Multilingual Instruction Tuning (\(\text{M}^3\text{IT}\)) dataset spanning 80 languages, surpasses InstructBLIP in video-language tasks based on the ROUGE-L score. Through these findings, it is important to incorporate multilingual data in VLM training, as it not only mitigates biases in web-scale datasets but also enhances model performance across diverse linguistic and cultural contexts.
Citation
@article{viet2025vlmdata,
title = {A Data-Centric Analysis on Advancing Vision-Language Models},
author = {Viet Nguyen},
year = {2025},
month = {Feb},
url = {https://quocviethere.github.io/blog/2025/vlmdata}
}